什么是生成式人工智能
生成式人工智能简介
传统的机器学习主要是预测式的(例如预测天气、房价、检测目标位置等),或者分析式的(例如对数据进行分类、标注等)。LLM 大语言模型则有所不同,它是生成式的,能够合成新数据,而不再局限于决策或预测。因此它在文本、图像、音乐和视频等需要生成内容的领域得到广泛使用。
2022 年后,人们发现可以通过提供示范和反馈,即使用提示词工程,显著提升模型的表现。
随着模型参数量的不断增加,例如 20-70 亿个参数,模型开始表现出新的能力,即能够生成创意型的新内容,并能够提供丰富的信息来回答一些开放性和挑战性的问题。
了解大规模语言模型
表征学习:模型不会被明确的指示要学习哪些特征,而是根据原始数据,自己找出那些重要的特征。
目前模型在处理数学或复杂的推理任务时,结果表现不佳。而且,我们还无法确定,通过不断增加参数规模,是否一定能够克服这个障碍。对于复杂和严谨的推理任务来说,正确的答案有可能在现有经验之外。而大模型的训练是基于过往提供的数据,推测一个可能性最大的答案,因此该答案一般是现有经验范围之内。
什么是文本到图像模型
有几种文生图的模型类型,其优缺点分别如下:
模型类型
图像质量
文本对齐
推理速度
训练难度
典型代表
GAN
高
中
快
高
AttnGAN, StyleGAN+CLIP
VAE
低~中
弱
快
低
VQ-VAE(组件)
自回归
高
强
慢
极高
DALL·E, Parti
扩散模型
极高
强~极强
中~慢*
极高
Stable Diffusion, Imagen
混合/新兴
极高
极强
中
高
FLUX.1, Ideogram
注:扩散模型可通过蒸馏、Few-step采样(如DDIM、LCM)显著加速。
扩散模型的实现过程貌似跟人类的作图过程有点类似,先从一张白纸开始(随机噪声),然后先画个轮廓,之后不断细化添加更细节,直至和脑海中想要的结果对齐(对于模型来说则是与输入的文字对齐)。
人工智能在其他领域的作用
文本、图像、音频、视频、结构化数据,这些数据类型都可以通过大模型来实现从 A 类型到 B 类型的生成。
输入 \输出类型
文本
图像
音频
视频
结构化数据(如表格、代码等)
文本 - 语言模型(如 GPT 系列)
- 文生图模型(如 DALL·E、Stable Diffusion)
- 文本转语音(TTS,如 Tacotron、VITS)
- 文本生成视频(如 Sora、Phenaki)
- 文本生成代码(如 Codex、CodeLlama)
图像 - 图像描述生成(Image Captioning)
- 图像编辑/增强
- 图像驱动语音合成(较少见)
- 图像插帧/视频预测
- 图像内容结构化(如图表识别、表格提取)
音频 - 语音识别(ASR,如 Whisper)
- 声音可视化(如声谱图生成图像,较少主流应用)
- 语音转换(Voice Conversion)
- 音频驱动视频生成(如 talking head 模型)
- 音频转结构化信息(如音乐转 MIDI、语音转命令)
视频 - 视频描述生成(Video Captioning)
- 视频风格迁移
- 视频中语音提取与合成
- 视频预测/补全
- 视频行为识别结果
结构化数据 - 数据解释/自然语言描述(如 NL2SQL 的反向)
- 表格/数据可视化生成
- 数据驱动语音播报
- 数据驱动动画/演示生成
- 数据清洗/转换
面向大模型的应用程序
超越随机鹦鹉
鹦鹉能够模仿人类说话,听起来就像真的一样,但鹦鹉本身并不理解这些话的意思。这也是大语言模型目前面临的困境,它并不真正的理解内容本身,因此它在一些复杂的逻辑推理和数学计算场景表现不佳。
缓解大模型局限性的一些方法:
提示词工程和微调:有针对性的训练数据让大模型更契合特定业务场景,结构性的提示词引导模型输出预期结果;
自我任务提示:有助于将复杂的问题拆分成多个小问题进行解决;
连接外部数据:避免训练数据过时的问题;
过滤和监控:对模型的输出进行过滤和调整,及时纠结小错误;
LangChain 简介
LangChain 通过提供合理的抽象,让开发大模型应用变得简单和灵活。其核心功能包括:
组件模块化:各模块可进行自由组合、替换、复用,从而更加易读和维护;
与外部服务进行连接;
实现智能体间的交互,取代孤立的 API 调用;
实现记忆和数据的持久性;
相关生态:
LangSmith:提供应用的测试、调试和监控功能;
LangChain 模板:模板仓库,方便开发人员复用,避免重复造轮子;
LangServe:方便部署和管理开发好的应用;
LangGraph:帮忙开发循环数据流和多角色互动的应用;
探索 LangChain 的关键组件
链
功能:将不同模块,组合成一个可以复用的管道(类似流水线),以实现特定的功能;例如:
LLMMath:实现数学相关查询
SQLDatabaseChain:数据库查询;
LLMCheckerChain:对输入进行验证;
RouterChain:根据输入判断应使用哪种工具;
智能体
链是多个模块的组合,智能体则是多个链的组合;
在智能体中,大模型可用来帮助完成推理任务。模型会收到提示词、可用工具、历史信息等内容,然后模型选择下一步的动作,可能是使用某个工具,也可能是给出最终的响应。
由于模型需要判断是否使用工具以及使用哪个工具,因此工具必须包括功能描述,以便模型进行判断。
记忆
智能体和链是无状态的,Memory 则用来保存每次执行之间的状态。
部分常见的记忆选项:
ConversationBufferMemory:在模型历史中存储所有消息
ConversationBufferWindowMemory:只保留最近的几条消息
ConversationKGMemory:将交流总结为知识图谱,并集成到提示中;
ConversationEntityMemory:存储对话中的一些事实;
另外也可以连接多种数据库,实现持久化存储;
工具
工具可帮助智能体实现特定的功能,例如内置的文档加载器、向量存储等;
部分常见的工具:
机器翻译;
计算器;
地图查询;
股票查询;
天气查询;
幻灯片制作;
表格处理;
搜索引擎;
维基百科;
在线购物;
知识图谱:从知识库中查询提取相关信息;
LangChain 如何工作
LangChain 封装了一系列组件,这些组件可相互协作,同时也可以自定义(只需实现统一的接口即可)。通过组件的共同协作完成复杂的任务。
主要组成部分包括:
准备数据
准备提示
基于用户的输入,代入模板,生成结构性的提示,引导模型生成预期结果;
内容生成
利用工具
记忆
监控
整合:借助以下两个工具串联以上各部分内容
LangChain 软件包结构
主要划分如下:
langchain-core:只包含基础组件的抽象和方法,以及几个核心组件,例如模型、向量存储、检索器等;
langchain:链、智能体、检索策略;
langchain-community:由社区维护的第三方集成;
合作伙伴各自的软件包
LangChain 和其他框架比较
工具
开发者
类型
主要用途
是否开源
AutoGen Microsoft
框架
多智能体协作系统构建
✅ 开源(MIT)
MetaGPT OpenBMB / 社区
框架
基于角色的多智能体软件工程自动化
✅ 开源(Apache 2.0)
LangChain LangChain Inc.
框架
构建 LLM 驱动的应用(链式调用、记忆、工具集成等)
✅ 开源(MIT)
LlamaIndex LlamaIndex Inc.
框架
数据连接与检索增强生成(RAG)
✅ 开源(MIT)
Dify Dify.AI 平台(低代码+API)
快速构建 AI 应用(支持 Agent、RAG、Workflow)
✅ 开源(部分)+ 商业版
Coze 字节跳动
平台(无代码/低代码)
构建聊天机器人、插件、工作流(面向 C 端和 B 端)
❌ 闭源(SaaS 平台)
LangChain 入门
设置依赖
开发环境适合用 conda,生产环境适合用 docker
特性
pip
Poetry
Conda
Docker
主要用途
安装 Python 包
依赖+项目管理
包+环境管理
应用容器化
环境隔离
❌(需 venv)
✅(自动)
✅
✅(操作系统级)
依赖解析能力
弱
强
强(含二进制)
依赖内部工具(如 pip)
锁文件支持
❌(需扩展)
✅(poetry.lock)
✅(environment.yml + explicit)
❌(但可通过固定版本实现)
支持非 Python 依赖
❌
❌
✅
✅(通过系统安装)
适合数据科学
一般
一般
✅
✅(配合 Conda/pip)
适合生产部署
❌
⚠️(需打包)
⚠️
✅
学习成本
低
中
中
高
集成模型
在环境变量中配置 API KEY 即可;
大模型交互
大语言模型
各家模型提供了相应的软件包来初始化模型,示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from langchain_openai import OpenAIfrom langchain_google_genai import GoogleGenerativeAIfrom langchain_community.chat_models import ChatTongyi"gemini-2.0-flash" )"qwen-turbo" , temperature=0.7 )"Tell me a joke about light bulbs!" )print (response)
模拟大模型
在开发应用时,对模型的调用不一定要使用真实的 API 接口,也可以返回模拟的响应结果。这样的好处是让结果更稳定,二来响应速度更快,也更省钱;
1 2 3 4 5 6 7 from langchain_community.llms import FakeListLLM"Hello" ])"Any input will return Hello" )print (result)
聊天模型
Langchain 为聊天对话设计了结构化的形式,以便区分不同角色的发言内容
1 2 3 4 5 6 7 8 9 10 11 from langchain_anthropic import ChatAnthropicfrom langchain_core.messages import SystemMessage, HumanMessage"claude-3-opus-20240229" )"You're a helpful programming assistant" ),"Write a Python function to calculate factorial" )
提示词
LangChain 支持提示词模板,可在模板中使用占位符变量,实际调用时,动态的替换变量内容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from langchain_core.prompts import PromptTemplatefrom langchain_google_genai import GoogleGenerativeAI""" Summarize this text in one sentence: {text} """ "gemini-1.5-pro" )format (text="Some long story about AI..." )print (result)
1 2 3 4 5 6 7 8 9 10 11 12 from langchain_core.prompts import ChatPromptTemplatefrom langchain_openai import ChatOpenAI"system" , "You are an English to French translator." ),"user" , "Translate this to French: {text}" ) "Hello, how are you?" )print (result.content)
链和 LCEL 表达式
使用链将多个动作串联起来
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from langchain_core.prompts import PromptTemplatefrom langchain_core.output_parsers import StrOutputParserfrom langchain_openai import ChatOpenAI"Tell me a joke about {topic}" )"topic" : "programming" })print (result)
文本到图像
可先使用文本 LLM 将用户输入的文本进行扩充,补充更丰富的细节信息。之后再提交给图像 LLM 生成图片。
1 2 3 4 5 6 7 8 9 10 11 12 13 prompt = PromptTemplate("image_desc" ],"Generate a concise prompt to generate an image based on the following description:" "{image_desc}" "halloween night at a haunted museum" )
Replicate
Replicate 是一个可以部署大模型的云平台,LangChain 已经封装了 API,可以很方便的调用已经部署好的模型。
1 2 3 4 5 6 7 8 9 10 from langchain_community.llms import Replicate"meta/llama-2-7b-chat:<模型ID>" "你好!介绍一下你自己。" )print (response)
图像理解
有些模型是多模态的,能够理解用户上传的图片,示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from langchain_core.messages import HumanMessagefrom langchain_openai import ChatOpenAI"gpt-4-turbo" , max_tokens=256 )"https://image_example_url" "type" : "text" , "text" : "What is this image showing" "type" : "image_url" ,"image_url" : {"url" : image_url,"detail" : "auto"
运行本地模型
除了调用云端的模型 API,LangChain 也支持在本地运行模型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from langchain_ollama import ChatOllama"deepseek-r1:1.5b" ,0 ,"system" ,"You are a helpful assistant." ,"human" , "What makes LangChain great for working with LLMs?" ),print (ai_msg.content)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from langchain_core.messages import SystemMessage, HumanMessagefrom langchain_huggingface import ChatHuggingFace, HuggingFacePipeline"TinyLlama/TinyLlama-1.1B-Chat-v1.0" ,"text-generation" ,dict (512 ,False ,1.03 ,"You're a helpful assistant" ),"Explain the concept of machine learning in simple terms" print (ai_msg.content)
构建客户服务应用程序
客服类应用程序涉及以下一些功能:
情感分类:识别客户的情绪;
生成摘要:抓取客户消息中的重点;
意图分类:理解客户想要达成的目标;
生成回复:根据历史回复数据和知识库,生成合适的回复;
map-reduce 方法
有些文档比较大,可能超过了模型的输入限制。此时可使用 map-reduce 方法进行处理。map 方法将文档拆分成多个小段,每个小段的长度满足模型的输入限制。之后大模型可以并行处理这些小段,生成摘要。最后通过 reduce 方法合并摘要,生成最终的结果。
构建得力助手
使用工具回答问题
使用工具
工具由以下几部分构成:
名称:str,必需
描述:str,必需,以便模型决定是否调用该函数;
函数:function,必需,执行的主体;
args_schema:Pydantic BaseModel,可选但推荐,有助于验证参数、少样本示例等;
返回方式:bool,是否将计算结果直接返回给用户
1 2 3 4 5 6 7 8 9 10 11 12 from langchain_community.tools import WikipediaQueryRunfrom langchain_community.utilities import WikipediaAPIWrapper1 , doc_content_chars_max=100 )print (tool.name)print (tool.description)print (tool.args)print (tool.return_direct)
1 2 3 4 wikipediafor when you need to answer general questions about people, places, companies, facts, historical events, or other subjects. Input should be a search query.'query' : {'description' : 'query to look up on wikipedia' , 'title' : 'Query' , 'type' : 'string' }}
自定义工具
自定义工具的几种方法:
@tool 装饰器
创建 BaseTool 子类
创建 StructuredTool 子类
工具装饰器
1 2 3 4 5 6 from langchain.tools import tool@tool def search (query: str ) -> str :"""Searches things online.""" return tool.run(querys=query)
1 2 3 4 5 6 7 8 9 10 11 12 from langchain.pydantic_v1 import BaseModel, Fieldclass SearchInput (BaseModel ):str = Field(description="The search query string." ) @tool("search-tool" , args_schema=SearchInput, return_direct=True def search (query: str ) -> str :"""Searches things online.""" return "LangChain is awesome!"
子类化 BaseTool 能够更灵活的自定义工具,常用于以下场景:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from typing import Optional , Type from langchain.tools import BaseToolfrom langchain.callbacks.manager import CallbackManagerForToolRun, AsyncCallbackManagerForToolRunclass SearchInput (BaseModel ):str = Field(description="The search query string." )class CustomSearchTool (BaseTool ):"custom-search-tool" "A tool that searches things online." Type [BaseModel] = SearchInputTrue def _run ( self, query: str , run_manager: Optional [CallbackManagerForToolRun] = None , ) -> str :"""use the tool synchronously.""" return "LangChain is awesome!" async def _arun ( self, query: str , run_manager: Optional [AsyncCallbackManagerForToolRun] = None , ) -> str :"""use the tool asynchronously.""" raise NotImplementedError("CustomSearchTool does not support async" )"What is LangChain?" )
StructuredTool 比 BaseTool 简单,但同时又比 tool 装饰器更灵活一些,相当于折衷;
1 2 3 4 5 6 7 8 9 10 11 12 13 from langchain.tools import StructuredTooldef search_function (query: str ) -> str :"""Searches things online.""" return "LangChain is awesome!" "structured-search-tool" ,"A tool that searches things online." ,True ,"What is LangChain?" )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class CalcatorInput (BaseModel ):int = Field(description="The first number." )int = Field(description="The second number." )def multiply (a: int , b: int ) -> int :"""Multiplies two numbers.""" return a * b"multiplier-tool" ,"A tool that multiplies two numbers." ,True ,dict (a=3 , b=5 ))
错误处理
当工具在调用过程中出现异常时,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from langchain_core.tools import ToolExceptiondef search_function (query: str ) -> str :"""Searches things online.""" if not query:raise ToolException("Query cannot be empty." )return "LangChain is awesome!" "structured-search-tool" ,"A tool that searches things online." ,True ,True ,
1 2 3 4 5 6 7 8 9 10 11 def custom_error_handler (error: ToolException ) -> str :return f"[错误] 无法执行操作: {error.args[0 ]} " "Multiply" ,"将两个整数相乘" ,
使用工具实现研究助手
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 mport dashscopeimport os"DASHSCOPE_API_KEY" )if not api_key:"请输入你的 DashScope API Key(阿里云)" , type ="password" )if api_key:if "messages" not in st.session_state:"role" : "system" , "content" : "你是一个乐于助人的助手。" }]for msg in st.session_state.messages:if msg["role" ] != "system" :"role" ]).write(msg["content" ])if prompt := st.chat_input("请输入你的问题" ):"role" : "user" , "content" : prompt})"user" ).write(prompt)def generate_response ():for chunk in model.stream(messages):yield chunk.contentwith st.chat_message("assistant" ):else :"请提供 DashScope API Key(可在阿里云控制台获取)" )
探索推理策略
大模型本身并不擅长复杂的符号推理,因此如果我们设计一个符号推理辅助的框架,将有助于模型完成一些更高级的复杂推理功能,例如:
任务规划:将一个大任务拆分成多个小任务;
多步推理:从一系列收集到的事实信息中获得结论;
数学推理:进行符号变换求解方程;
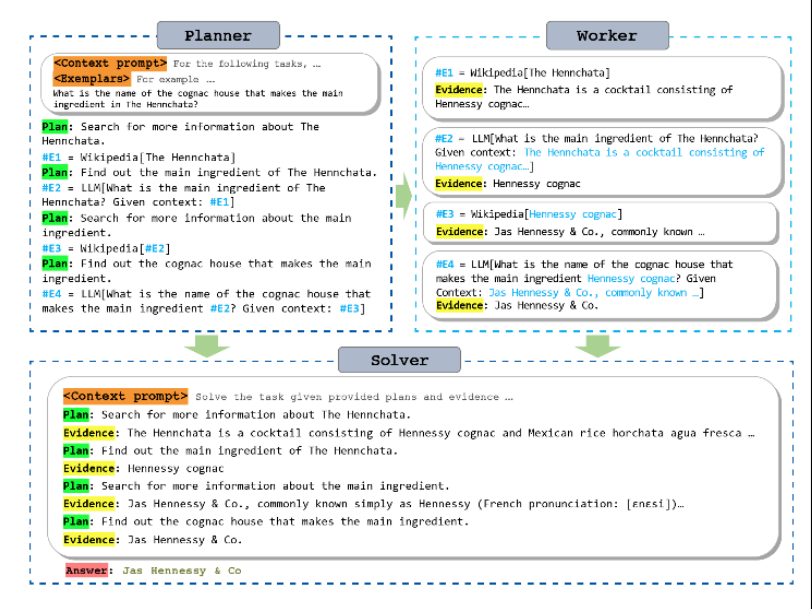
规划器(Planner)、执行器(Worker)、求解器(Solver)的协作示例:
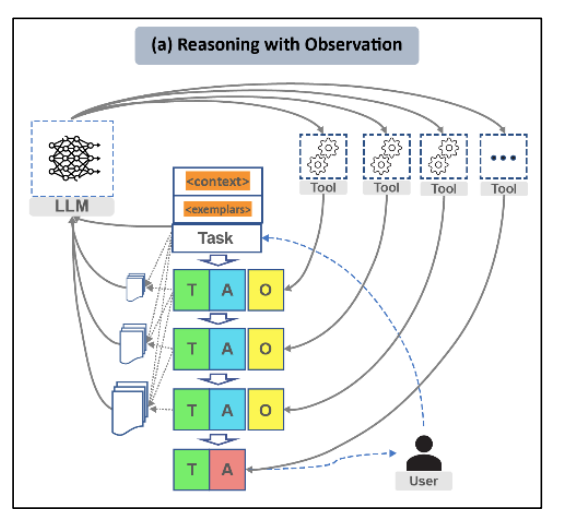
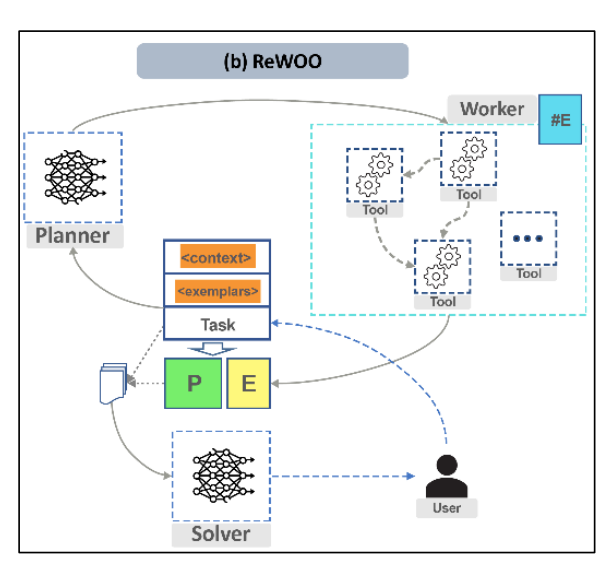
有两种推理策略:
方法一:依赖观察推理(零样本智能体):模型做一个判断,工具执行,智能体将工具的执行结果做为新的信息,交给模型再次判断。重复这个循环,直到得出最终的结果。这个方法的优点是直观容易理解,缺点是随着循环次数增多,上下文会越来越大,成本很高。
方法二:不依赖观察推理,而是使用规划+求解(ReWOO,Reason without Observation)。规划器模型先规划任务,然后调用不同的工具来完成每一个规划的任务,收集信息。最终汇总规划列表和证据,统一让求解器模型生成最终的输出。其中规划器和求解器可以各自使用专用的模型,以获得更好的效果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from typing import Literal from langchain import hubfrom langchain.agents import create_react_agent, AgentExecutorfrom langchain.chains.base import Chainfrom langchain_openai import ChatOpenAIfrom langchain_experimental.plan_and_execute import (from langchain_community.tools import load_toolsLiteral ["zero-shot-react" , "plan-and-execute" ]def load_agent (tool_names: list [str ], strategy: ReasoningStrategies = "zero-shot-react" ) -> Chain:0 , streaming=True )if strategy == "plan-and-execute" :True )return PlanAndExecute(planner=planner, executor=executor, verbose=True )"hwchase17/react" )True , prompt=prompt)return AgentExecutor(agent=agent, tools=tools)
没有哪个策略是万能的,不同的策略有不同的使用场景。当使用场景不对时,不可避免会出现一些失败,例如步骤规划遗漏、语义理解错误、计算错误等;
从文件中读取结构化信息
LangChain 内置的输出解析器,支持从文件中提取出结构化的信息,例如 PDF、CSV、XML、YAML 等;
有时候大模型的信息提取并不完美,会遗漏一些信息。
通过事实核查减少幻觉
这个世界上充斥着各种虚假信息,如果大模型不加分辨的将它们做为自己的数据来源,其所得出的结论自然也是不真实的。为避免出现这种虚假的幻觉,有必要对信息进行核查。
核查的原理并不复杂,跟人类的行为类似,涉及以下三个动作:
判断哪些信息需要核实;
搜集关于该信息的正反两方面的观点和数据;
整合以上信息,进行评估判断,得出结论;
LangChain 有专门内置了一个链用来做事实核查的工作,示例如下:
1 2 3 4 5 6 7 from langchain.chains import LLMCheckerChainfrom langchain.llms import OpenAI0 )"What type of mammal lays the biggest eggs?" True )
它背后的提示词设计大致如下:
1 2 3 4 5 """ Here's the statement: {statement} Make a bullet point list of the assumptions you made when producing the above statement. """
1 2 3 4 5 6 """ Here is a bullet point list of assertings: {assertions} For each assertion, determine whether it is true or false. If it is false, explain why. """
1 2 3 4 5 """ In light of the above facts, how would you answer the question {question} """
以上 LLMChecker 提示词工程并不能保证最终的答案一定是正确的,它只是尽可能减少错误的概率。
构建聊天机器人
什么是聊天机器人
一些应用场景:
个性化教育的虚拟导师;
法律问题咨询回复;
心理问题咨询回复;
在线购物售后客服;
医疗问题咨询回复;
虚拟助理:帮忙起草邮件、消息回复、提醒事项等;
招聘助理:自动筛选和分析简历;
有两种聊天机器人,一种是被动型的,会话由用户主动发起,然后它进行回复,满足用户需求。还有一种是主动型的,它根据上下文预测用户的需求,然后主动发起会话,主动创造满足需求的机会。
从向量到 RAG
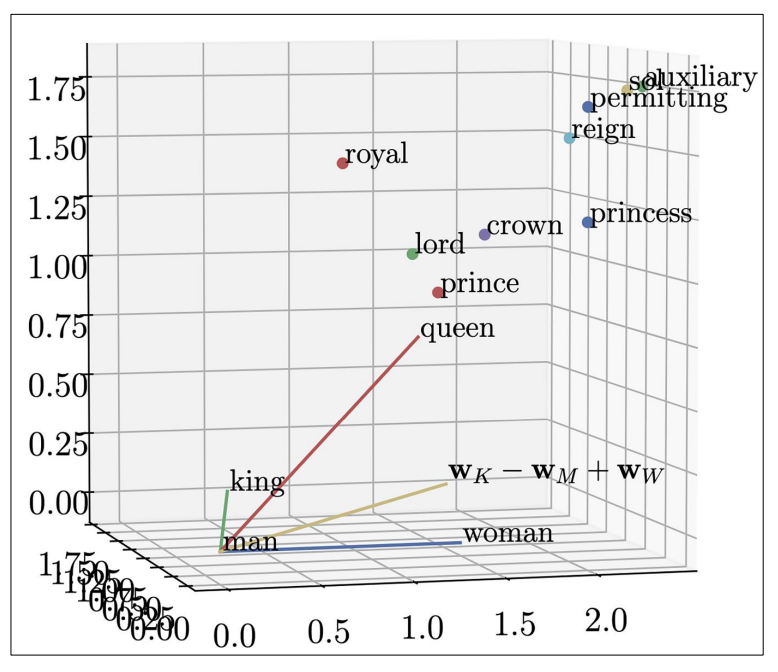
向量嵌入
嵌入即向量化,将内容转换成用多维度的数字来表示。多维的数字有些类似空间的概念,通过计算点之间的距离,可以区别它们的相似性,甚至可以进行延伸,例如向量 king - man + woman 的值很接近 queen;
LangChain 的嵌入
LangChain 提供了一个 Embedding 基础类,各家模型开发商基于该基础类设计自己的嵌入类,以适应不同模型自身的嵌入转换方法。
即使是同一家模型开发商,可能也存在参数规模大小不同的模型。每个模型有可能使用不同的嵌入转换方法,以便实现模型的最佳性能。
1 2 3 4 5 from langchain_openai import OpenAIEmbeddings"text-embedding-3-large" )"This is a test text."
向量存储
向量一般基于相似度进行搜索,因此如何存储向量很重要,因为设计合理的索引能够极大的提高搜索效率。
向量索引
向量搜索的目标,是找出相似的内容。因此存储的核心原理是将类似的东西,凑在一起存储,这样一抓抓一窝。
为提高写入速度以及充分利用存储空间,初步想法是在索引层面建立虚拟的空间结构,通过树或图来实现分门别类,底层存储则仍然跟传统存储方法类似。
一些常见的搜索算法:
点积量化:Product Quantization,将向量空间逐级划分为更小的子空间,这样搜索起来有点类似二分查找。子空间的划分有多种方法,例如:
k-d tree 树:k 维树,每一维做一次二分查找,对于低维向量效果不错,但维数越高,效果越来越差;
嵌套超球
ball tree:球树,二叉或多叉,每个数据点仅会出现在一个叶节点上;
cover tree:覆盖树,多层嵌套,同一个数据点可能会出现在多个层中;
局部敏感哈希:LSH,locality sensitive hashing 将相似的数据点映射到相同的哈希桶中;为避免假阳性或者假阴性,会使用多个哈希函数。
分层导航小世界:HNSW,Hierarchical Navigable Small World
每个数据节点先按指数概率随机分配层数,这样会导致越顶层的节点数越少,越底层的节点数越多。0 层拥有所有的数据节点;例如第 0 层的概率是 1,第 1 层的概率是 1/10,第 2 层的概率是 0.01,第3 层的概率是千分之一,以此类推。层数是按指数概率进行分配的,比如将概率基数定为 16,那么出现在第 10 层的概率是 (1/16)^10;假设总共有100亿个数据节点,那么出现在第 10 层的节点数 = 100亿 * (1/16)^10 < 1;
每个数据节点在每层找最邻近的若干个(例如32个)节点做为邻居;这意味着这些邻居会成簇集中,越顶层簇数越少,越底层簇数越多。不同节点之间在下一层的簇是存在重叠的数据节点的,因为它们可能互为邻居。
0 层在使用贪心算法遍历邻居后,不再像其他层只返回某个最邻近节点,而是会返回一个 top-k 列表做为结果;
张三想在这个世界上找一批和自己长得比较像的人,整个搜索过程有点类似:
全世界每个国家派出一个代表,张三先在这批代表里面比对,哪个国家的人和自己长得最像;
假设上一步的结果是中国代表李四,接下来张三从李四所在的微信群里面继续找第二批候选人。这个微信群的群主是李四,是李四之前按照面相相似度组的群。
每个群的成员,都有外一个以自己做为群主的微信群,同时群主本人也是别人的微信群的成员。
就这样逐级向下寻找,直到最后一层(0层)的群,从中选出最像的 n 个人,然后停止查找,返回结果。
HNSW 很好的平衡了性能和复杂度,因此使用广泛,是 Milvus、Pinecone、Qdrant 的默认索引之一(通常向量数据库会同时支持多种索引算法,这样用户可以根据使用场景,使用最合适的算法);
向量数据库
向量数据库的一些使用场景:
个性化推荐;
异常数据识别:例如检测危险的数据输入、欺诈等;
自然语言处理:例如语义分析、情感分析、文本分类等;
向量数据库的一些特点:
高效的相似性搜索;
支持高维数据;
支持一些高级的搜索功能(这些功能在常规数据库不容易实现,比如内容推荐);
一些主流的开源向量数据库:Milvus、Pinecone、Qdrant、Chroma、Weaviate 等;
LangChain 有一个 vecstores 模块用来实现向量存储,一般各向量数据库的接口放在该模块中;
1 2 3 4 5 6 7 8 9 10 11 12 13 from langchain.vectorstores import Chromafrom langchain_text_splitters import CharacterTextSplitterfrom langchain_openai import OpenAIEmbeddings"I am a very long document." 500 , chunk_overlap=0 , separator="/n" )"text-embedding-3-large" )"I am a very long document." , k=1 )
文档加载器
针对不同格式的内容,LangChain 内置了很多对应的加载器,例如:
TextLoader
WebBaseLoader
ArxivLoader
YoutubeLoader
ImageCaptionLoader
WikipediaLoader
1 2 3 4 5 from langchain.document_loaders import TextLoader"./demo/data/demo.txt" )
1 2 3 4 5 6 from langchain_core.output_parsers import StrOutputParserfrom langchain_anthropic import ChatAnthropicfrom langchain_community.document_loaders import ArxivLoader"2201.11903" , max_results=3 ).load()
1 2 3 4 5 6 from langchain import hub"hwchase17/anthropic-paper-qa" )print (prompt)
1 2 input_variables=['text' ] input_types={} partial_variables={} metadata={'lc_hub_owner' : 'hwchase17' , 'lc_hub_repo' : 'anthropic-paper-qa' , 'lc_hub_commit_hash' : '0b8e75415e4d1314431e2a22176dce33c65375d4b3be7a2e21c91819da6dfbf7' } messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['text' ], input_types={}, partial_variables={}, template='Here is an academic paper: <paper>{text}</paper>\n\nPlease do the following:\n1. Summarize the abstract at a kindergarten reading level. (In <kindergarten_abstract> tags.)\n2. Write the Methods section as a recipe from the Moosewood Cookbook. (In <moosewood_methods> tags.)\n3. Compose a short poem epistolizing the results in the style of Homer. (In <homer_results> tags.)\n4. Write a grouchy critique of the paper from a wizened PI. (In <grouchy_critique> tags.)' ), additional_kwargs={})]
LangChain 的检索器
检索器(Retriever)的职责是完成查询,查询的目标可以是本地的数据库,但也可以是网页或者其他数据来源。针对不同的来源,LangChain 内置了一些常用的检索器,用于完成不同内容的检索查询,例如 kNN 和 PubMed。
kNN 检索器
1 2 3 4 5 6 7 8 9 10 from langchain_community.retrievers import KNNRetrieverfrom langchain_openai import OpenAIEmbeddings"cat" , "dog" , "fish" , "bird" , "elephant" , "giraffe" , "lion" , "tiger" ]3 ,"cat" )
PubMed 检索器
PubMed 是一个用于医学文献领域的检索器
1 2 3 4 5 6 from langchain_community.retrievers.pubmed import PubMedRetriever"cancer" )for document in documents:print (document.metadata["title" ])
自定义检索器
继承 BaseRetriever 类,实现一个 get_relevant_documents 的方法。根据查询参数,返回相关文档
1 2 3 4 5 6 7 8 9 10 11 12 13 class MyRetriever (BaseRetriever ):"""My retriever.""" def get_relevant_documents ( self, query: str , ) -> List [Document]:"""Get relevant documents.""" return relevant_documents
其他
多路召回
主要用于推荐系统的场景,综合多个不同的维度,给用户推荐某些内容和商品。例如最热门、同类产品、浏览记录、相似用户、打折促销、搜索时间段(白天或晚上)等。多路召回主要负责广度,之后将召回的结果交给其他算法排序(例如先去重,然后给不同的维度计算权重,最后得到一个排名)。
BM25 算法
best matching 25,BM25 用于判断某个查询 query (可能包含多个单词)与某个文档的相关性。根据相关性得分找出最匹配的 25 项。主要用于关键词的稀疏检索。另外还在基于语义的 Embeddding 稠密检索。二者可以结合使用,实现混合召回。
TF-IDF(词频-逆文档频率,Term Frequency-Inverse Document Frequency)的计算公式如下:
T F − I D F ( t , d ) = T F ( t , d ) × I D F ( t )
其中:
T F
表示某个单词 t 在文档中出现的次数;一般取归一化的值,以减少长文档的天然优势;
IDF 表示单词 t 在所有文档中的稀缺程度;
标准 IDF 的计算公式为:
IDF ( t ) = log ( N DF ( t ) )
其中:
N 表示总的文档数量;
DF 表示包含单词 t 的文档数量;
相比 TF-IDF,BM25 做了两个改进:
词频饱和:避免频率和相关性线性相关,而是边际递减;
文档长度归一化:避免长文档占据优势,因为文档越长也不一定代表相关性越高;
优点:简单,无须训练,计算高效;
缺点:基于关键词而不是语义进行匹配,效果依赖分词质量,结果不稳定;对拼写错误、模糊搜索不够友好;
IDF 计算公式变为:
IDF ( t ) = log ( N − n ( t ) + 0.5 n ( t ) + 0.5 + 1 )
其中:
BM25 计算公式为:
Score ( D , Q ) = ∑ i = 1 n IDF ( q i ) ⋅ TF ( q i , D ) ⋅ ( k 1 + 1 ) TF ( q i , D ) + k 1 ⋅ ( 1 − b + b ⋅ | D | avgdl )
其中:
TF ( q i , D )
是单词
q
在文档 $ D $ 中出现的次数
( k_1 ):控制词频饱和程度的参数,通常取值范围为 1.2 ~ 2.0
( b ):控制文档长度归一化强度的参数,通常设为 0.75
( |D| ):文档 ( D ) 的长度(通常以词数计)
倒排索引
正排索引:基于 ID 找文档;
倒排索引:基于文档中的关键字,找文档 ID;
BM25 需要通过倒排索引,找到关键词对应的文档 ID,然后找出文档,以便能够计算相关性得分。
词袋模型
将句子或文档,看成是单词的组合(不考虑顺序)。所有单词即构成词汇表,之后可用于将句子或文档向量化,方便进行相关性检索。
混合检索
同时使用稀疏和稠密两种方法进行检索,之后有两种方法整合检索结果:
方法一:直接融合,去重后按一定规则(加权、RRF)进行打分排序;
方法二:线性组合,score = α * BM25 + (1−α) * CosineSimRRF
倒序融合 RRF
RRF:Reciprocal Rank Fusion,倒序融合。加总各个结果在各自的子列表中的排名得分后,进行总的排序;背后的核心思路是一个结果在子列表中的排名越靠前,那么相关性越高。如果一个检索结果在所有子列表中都排名靠前,那么应该给它高分,排名靠后则给低分。
RRF ( d ) = ∑ i = 1 n 1 k + rank i ( d )
k 是平滑系数,通常设置为 60(经验值);
优点:计算简单高效、无须训练、鲁棒性好;常用于粗排场景,之后还可以再次进行细排;
交叉编码 Cross-Encoder
粗排结果通常使用 Bi-Encoder 双塔模型获得,此时 query 和 document 是各自编码,使用点积或余弦计算相似性,缺少二者每个单词之间的交叉注意力,因此只有一个大概的相关性。Cross-Encoder 的理念是将 query 和 document 组合起来,输入 Transformer 编码器,通过算 query 和 document 之间的自注意力,获得一个更准确的相关性分数,从而实现精排。
优点:准确度高
缺点:计算慢,因为不能预计算,所以不适合处理大规模的重排。
graph LR
A[用户问题] --> B{召回阶段}
B -->|BM25| C[候选文档 Top-100]
B -->|Dense Retrieval| D[候选文档 Top-100]
C & D --> E[去重合并]
E --> F[Cross-Encoder 精排]
F --> G[Top-5 最相关文档]
G --> H[LLM 生成答案]
有时候 Cross-Encoder 在一些垂直领域的表现不如预期,此时可能需要考虑对模型进行微调,以便模型可以学会垂直领域的知识,提高相关性判断的准确性。
负采样
负采样是一种训练嵌入模型的技术,正常情况下我们给模型提供正确答案,让它学习正确的参数。如果我们同时提供一些似是而非的错误答案,那么有助于模型参数更快更准确的收敛。
有几种负采样的方法:
随机负采样:效果一般;
内负采样:同批次的其他答案作为错误答案;优点是简单,缺点是可能误判,因为其他答案有可能是相关的。
高难度负采样:使用检索结果 top-k 之外的高排名答案作为负采样;
最大边际排序损失
Margin Ranking Loss,一种损失函数,可用来训练嵌入模型的。需要提供正负样本对。然后模型需要不断调整参数,直到正样本和负样本的得分差,大于指定的阈值(边际值),以便能够拉开二者的差距。
嵌入微调
常规的嵌入模型是面向通用场景,对于垂直领域的知识来说,有可能检索效果不佳。此时需要微调嵌入模型,以便让其能够返回更准确的匹配结果。
LLM 只读取检索返回的文本内容,不直接读取 Embedding 模型的向量。因此对 Embedding 模型进行微调,并不会影响 LLM 的回答质量。但是微调 Embedding 也是有风险的,因为一些用词在微调后,可能具备了专业含义。此时如果用户提问的正好是非专业的问题,则有可能造成检索结果的不匹配。微调的数据质量也很重要,如果质量不高,则也有可能造成语义扭曲。
参数调优
一些常见的调优方法:
文本拆分参数:chunk_size、overlap
查询重写;
提示词模板;
检索指标
Recall@k:假设正确的结果有 100 个,检索返回的结果中,包含多少个正确结果;这个指标越高,表示找的越全。
Precision@k:假设使用 top-5,返回的 5 个结果中,有 3 个是正确的,那么指标值为 0.6,用来表示找得准不准;
k 的常见取值为 1,3, 5, 10,并不是越大越好,因为 LLM 的上下文窗口可能不允许;
MRR:mean reciprocal rank,平均倒数排名;检索返回的结果中,第一个跟查询相关的结果,其排名位置的倒数。可用来评估排序质量(貌似也可顺便评估检索质量,如果总是 0,则说明没有命中);这个指标通常用来评估只需要回答单个答案的场景。
最大边际相关性
MMR:Max Margin Relevance,最大边际相关性;一种向量检索策略,考虑相关性的同时,还考虑结果的多样性。避免因为单一的相关性导致结果出现很多冗余重复。简单来说是“尽可能挑选相关性的,但别跟已挑好的太过相似”;
使用检索器实现聊天机器人
使用检索器实现聊天机器人涉及三个部分:
使用文档加载器读取领域知识;
将知识转换成向量存储到数据库中;
聊天回复时,使用检索器从数据库中读取知识,作为上下文和问题一起输入大模型生成答案;
为提高上下文的 token 使用效率,检索器支持对上下文进行压缩,常见的压缩方法包括:
LLMChainExtractor:使用模型从检索到的文档中提取内容
LLMChainFilter:使用模型过滤掉无关文档
EmbeddingsFilter:基于相似性得分进行过滤;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 from langchain_community.vectorstores.docarray import DocArrayInMemorySearchfrom langchain_community.embeddings.huggingface import HuggingFaceEmbeddingsfrom langchain_text_splitters import RecursiveCharacterTextSplitterfrom langchain_core.retrievers import BaseRetrieverfrom langchain.schema import Documentfrom langchain.retrievers.document_compressors.embeddings_filter import EmbeddingsFilterfrom langchain.retrievers import ContextualCompressionRetrieverdef configure_retriever ( docs: list [Document], use_compress: bool = True """ 配置并返回一个文档检索器 Args: docs: 文档列表,用于创建检索器 use_compress: 是否使用嵌入过滤器进行上下文压缩,默认为True Returns: BaseRetriever: 配置好的文档检索器实例 """ 1500 , chunk_overlap=200 )"sentence-transformers/all-MiniLM-L6-v2" "mmr" , search_kwargs={"k" : 3 , "fetch_k" : 4 }if not use_compress:return retriever0.8 return ContextualCompressionRetriever(
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def configure_chain (retriever: BaseRetriever ) -> Chain:""" 配置并返回一个链,用于处理用户输入并生成响应 Args: retriever: 文档检索器实例 Returns: Chain: 配置好的链实例 """ "gpt-3.5-turbo" , temperature=0 , streaming=True )"chat_history" , return_messages=True )4000 return ConversationalRetrievalChain.from_llm(True ,
对话记忆
对于聊天机器人来说,保持一定的历史对话记录是很重要的。LangChain 有多种管理记忆的方法,分别如下:
临时会话记忆
ConversationBufferMemory:简单缓存,保留所有历史对话;
ConversationBufferWindowMemory:保留最近的 N 轮对话;
ConversationTokenBufferMemory:保留多少个 Token 以内的对话(用来控制上下文长度);
ConversationSummaryMemory:从历史对话中提取摘要,节省上下文的长度;
ConversationSummaryBufferMemory:摘要 + 最近 N 轮对话
持久会话记忆:需要外部数据库进行存储
RedisChatMessageHistory
PostgresChatMessageHistory
以上多种对话缓存机制可以同时使用,示例如下:
1 2 3 4 5 6 7 8 9 10 11 llm = OpenAI(temperature=0.9 )"chat_history_lines" , input_key="input" "chat_history_summary" , input_key="input"
Memory 默认将对话历史存放在内存中,但也支持存储在外部数据库,例如 Redis;示例如下:
1 2 3 4 5 from langchain_community.chat_message_histories import RedisChatMessageHistory"user_123" , url="redis://localhost:6379" )True )
在创建 Agent 或 Chain 时,只需要将初始好的 Memory 做为参数传入即可。之后 Chain/Agent 在向 LLM 发送请求前,会自动从 Memory 中读取历史会话信息,然后放到 Prompt 模板的占位符中。在得到 LLM 的响应后,又会将该响应存入 Memory。
调节响应
大模型的答案需要合乎法律和道德规范,因此有必要设立一个检查机制,包括:
过滤仇恨言论、攻击性内容等
符合公司的品牌形象;
防止用户的非法输入和滥用;
遵守法律;
LangChain 有内置了一个 OpenAIModerationChain 用于实现此目标,它会对待输出内容进行检查,确保内容安全。如果内容违反规则,则会触反一些警报机制或错误信息。
防护
用来控制大模型的回答方向,包括:
避免讨论敏感的政治议题;
预定义会话路径:确保模型的聊天按照设定的流程进行,而不是随意发挥;
设定语言风格;
提取结构化数据;
利用大模型开发软件
软件开发与人工智能
使用大模型来辅助软件开发已经取得了非常大的进步,尤其是在生成单一功能的代码片段方面。目前这个领域发展很迅速,各种技术在不断的迭代。最终能够达到什么样的高度,还有待观察。
一些常见的使用场景:
代码自动补全;
自动生成测试代码;
代码解释;
代码搜索;
漏洞排查;
自动生成功能代码(过于复杂的功能暂时不行);
使用大模型编写代码
一些辅助开发的 IDE 插件:
插件名称
特点
适用场景
是否免费
GitHub Copilot OpenAI 驱动,根据注释/上下文生成高质量代码
快速原型、算法实现、多语言支持
❌($10/月,学生免费)
Amazon CodeWhisperer AWS 官方出品,集成云服务代码+安全扫描
AWS 云开发、安全审计
✅(个人免费)
Tabnine 支持本地模型,隐私强,响应快
敏感项目、离线环境
✅(基础功能免费)
通义灵码(TONGYI Lingma) 阿里云出品,中文友好,支持代码优化
国内团队、阿里云生态
✅(个人免费)
CodeGeeX 清华开源,完全免费,支持代码翻译/解释
学生、跨语言迁移
✅
Bito 基于 GPT-4,支持代码解释、测试生成、技术问答
新手学习、遗留代码维护
✅(注册即用,API 自费)
Codeium 免费开源,支持代码搜索与复用
开源贡献、代码复用
✅
一些集成 AI 的 IDE:
自动化软件开发
使用大模型进行软件的自动开发有两种实现方式:
规划任务,将开发任务拆解成多个小任务。每个任务按照“计划 -> 行动 -> 审查”的模式进行。如果审查通过,则进入下一个子任务;如果审查不通过,则调整方案,重新循环;
多个不同角色的智能体相互协作,类似 MetaGPT;
1 2 3 4 5 6 7 8 9 10 11 from metagpt.software_company import SoftwareCompanyfrom metagpt.roles import ProjectManager, ProductManager, Architect, Engineerasync def startup (idea: str , investment: float = 3.0 , n_round: int = 5 ):"""Run a startup. Be a boss""" await company.run(n_round)
在 LangChain 中直接集成自动代码开发功能是比较危险的,因为生成的代码拥有很大的权限,可以随意访问电脑上的任意文件。因此更好的做法是让其在沙箱中执行,与本地环境进行隔离。
用于数据科学的大模型
定制大模型及其输出
调节大模型
控制大模型输出的方法:
训练阶段
微调:使用特定数据集进行二次训练,提高模型在特定任务上的性能表现;
提示工程
人工监督:人机反馈回环,强化学习 RLHF
强化学习
RLHF(基于人类反馈的强化学习)的三个步骤:
监督预训练
奖励训练:设计一套打分标准,对模型的输出进行打分;
RL 微调:设计 RL 算法,引导模型实现奖励最大化;
低轶适应
参数高效微调(PEFT,Parameter Efficient Fine Tuning)是一种微调方法,其原理是只微调少量参数(例如少于1%)来提高模型性能,这样训练量更小。其背心的原理在于,针对特定任务,需要变更的模型参数是稀疏的。因此,我们可以基于这个事实,找出这些少量待变更的参数即可。
低秩适应(LoRA,Low-Rank Adaptation)是 PEFT 的一种实现方式。它冻结原始参数,并给每一层 Transformer 引入一个可训练的秩分解矩阵;
秩分解:将一个大矩阵
W
近似表示为两个低秩矩阵的乘积。假设大矩阵的尺寸是 m x n,那么可以拆分成 m x r 和 r x n 两个小矩阵的乘积。原本需要训练的参数量是 m x n,拆分后,需要训练的参数量为 m x r + r x n;如果 r 设置得非常小,那么需要训练的参数将大大减少,例如可以减少 100 倍;
示例:768 x 768 的大矩阵,需要训练的参数量是 768×768=590K;拆分成 768 x 8 和 8 x 768 的两个矩阵后,需要训练的参数量变成了 768 * 8 + 8 * 768 = 12K,相比原始参数,数量少了约 50 倍;
QLoRA 是在 LoRA 的基础上使用了量化方法,使用更少的位数来表示参数(例如 32 位的浮点数改用 4 或 8 位整数来表示),进一步节省了内存要求;
提示工程
一些常用的技术:
提示设计:基于预期的行为,提供自然语言进行指导,让模型输出预期结果;
限制词元:强制排除或者包含某些特定的词元;
元数据:提供一些高级信息,例如目标受众、数据类型、语言风格等;
前缀调整:Prefix Tuning,在模型中预置可训练向量,放在输入层前面,作用有些类似于提示词;
输出缩放:在模型中预置可训练向量,对模块的输出进行缩放,例如 IA3;
微调
预训练的模型在出厂发布前,一般会针对特定的使用场景进行一次全量微调。所以常规的微调一般只需在出厂模型的基础上,使用特定数据,进行局部参数的高效微调。如果训练数据很大且类型不够多样,进行全量微调有一定的风险,因为有可能导致模型原本学习到的能力的降低甚至遗忘。
使用场景
微调主要有以下几种使用场景:
对话风格:回答的语气、用词等,塑造某种人设或情感风格,让模型的回答具备个性化的特点;
知识灌注:让模型学习一些垂直领域的基本常识和概念,这样有助力提升其推理能力;细节知识可由 RAG 辅助;
推理能力:通过提供特定领域的推理示例,提升模型处理特定领域复杂任务的推理能力;
Agent 能力:让模型能够更高的和其他外部工具进行配合;知道有哪些工具可以用,在什么场景下使用等等;
对于微调来说,最重要的不是方法或工具,最重要的是如何准备高质量的数据;
云服务
一些微调模型的平台
Colab
AutoDL,国内智谱华章运营,性价比更高;
微调框架
一些开源的微调框架:
框架
特点
GitHub / 文档
LLaMA-Factory 支持 100+ 开源模型(Qwen、Llama3、Gemma 等),集成 LoRA/QLoRA/DPO/PPO,带 Web UI(LlamaBoard),中文文档完善
GitHub | 文档
Hugging Face Transformers + PEFT 行业标准组合,生态最大,支持所有主流模型,配合 trl 可做 DPO/SFT
HF 官网
Unsloth 单机单卡,训练加速神器,显存降低 60%+,速度提升 2 倍,精度无损,兼容 HF 生态;
GitHub
SWIFT(ModelScope) 阿里系开源框架,支持 300+ LLM + 50+ 多模态模型,覆盖训练→推理→评测全链路
GitHub
XTuner 中文社区活跃,与 LMDeploy/OpenCompass 深度集成,适合国产模型(如 InternLM)微调
GitHub
Firefly 配置文件驱动,支持预训练/SFT/DPO,小白也能快速上手
GitHub
Axolotl 高度可配置 YAML 微调框架,适合科研反复实验
GitHub
大模型性能评估框架:EvalScope,可以从魔搭直接下载数据集进行评测,也是阿里出品。
Linux 和 Win 都能很方便的进行单机单卡微调,但如果是单机多机,则 Linux 支持更好。
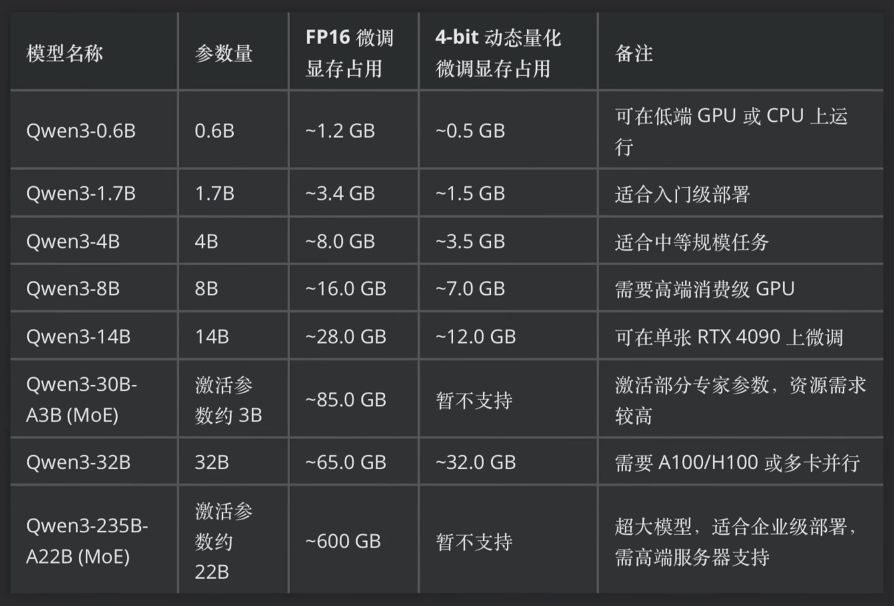
微调 Qwen3 系列模型的硬件要求:
如何准备微调数据集
针对不同的业务场景,需要准备不同格式的数据集。例如问答、推理、MCP 这三个场景所需要准备的数据集格式是不同的。大模型工作原理的本质是基于已知的输入,去预测下一个输出。因此真正提交给大模型的数据,也是这种格式。当然,它里面会包含一些特殊字符(类似编程语言中的关键字)标记某段内容的性质。
每个模型所使用的特殊字符及作用可能不同,详细可参考模型的配置文件 tokenizer_config.json,里面一般会有详细的说明。
问答类型
假设有以下 JSON 格式的训练数据集
1 2 3 4 5 { "instruction" : "你是一名乐于助人的助手" , "input" : "你好" , "output" : "你好,请问有什么可以帮助您" }
它实际输入给模型的数据会转换成如下内容:
1 2 3 4 5 6 7
MCP 类型
MCP 工具类型的训练,模型的预期返回内容是 JSON 格式,以下是训练数据的示例:
1 2 3 4 5 {"instruction" : "你是一名乐于助人的助手。当用户查询天气的时候,请调用 get_weather 函数进行天气查询" ,"input" : "你好,请帮我查询深圳的天气" ,"output" : {"name" :"get_weather" , "arguments" : {"location" : "shenzhen" }}
经过微调框架对以上 JSON 进行格式转换后,实际输入模型的数据内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 <|im_start|>systemfunctions to assist with the user query.function signatures within <tools></tools> XML tags:"name" : "get_weather" , "description" : "查询指定城市的天气信息" , "parameters" :"type" : "object" , "properties" : {"location" : {"type" : "string" , "description" :"要查询天气的城市名称" }}, "required" : ["location" ]}}function call, return a json object with function name and arguments"name" : <function-name>, "arguments" : <args-json-object>}"name" : "get_weather" , "arguments" : {"location" : "北京" }}
思维链类型
训练数据的格式示例,添加了 reasoning_content 字段,用来表示思维过程。
1 2 3 4 5 6 7 8 9 10 11 { "system" : "你是一名乐于助人的助手" , "conversations" : [ { "role" : "user" , "content" : "你好,好久不见" } ,{ "role" : "assistant" , "content" : "是的,好久不见,近来可好" , "reasoning_content" : "好的,用户发来“你好,好久不见”,我需要回应。首先,用户可能希望得到亲切的回复,所以应该使用友好的语气。" } ] }
实际输入模型的数据内容
1 2 3 4 5 6 7 8 9 <|im_start|>system
思考过程 + 系统提示 + 工具调用
1 2 3 4 5 6 7 8 9 10 11 {"system" : "你是一名乐于助人的助手" ,"conversations" : ["role" : "user" , "content" : "你好,请帮我查询深圳的天气" },"role" : "assistant" ,"content" : {"name" : "get_weather" , "arguments" : {"location" : "北京" }},"reasoning_content" : "好的,用户问深圳今天的天气,我应该尝试调用工具 get_weather,并将参数设置为北京。"
转换后输入大模型的内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <|im_start|>systemfunctions to assist with the user query.function signatures within <tools></tools> XML tags:"name" : "get_weather" , "description" : "查询指定城市的天气信息" , "parameters" :"type" : "object" , "properties" : {"location" : {"type" : "string" , "description" :"要查询天气的城市名称" }}, "required" : ["location" ]}}function call, return a json object with function name and arguments"name" : <function-name>, "arguments" : <args-json-object>}"name" : "get_weather" , "arguments" : {"location" : "北京" }}
数据清洗
有很多开源的数据集可以用来辅助微调,但是它们的格式可能各不相同。在微调前,需要使用函数将它们转换成当前模型的提示词模板所规定的格式。有些转换有现成的库可以使用,有些则需要自己编写函数手动转换一下。
混合数据集
功能越复杂的模型,如果微调的数据集不匹配,越有可能在微调后失去原本的复杂能力。如果想要保持模型原本的能力,则在准备数据集,要特别小心。在准备新的领域知识的数据时,也要保留很大一部分旧有的训练数据集。这样才能够避免能力的遗忘。
不同的数据集的条数可能存在很大的差别,在创建混合数据集则,需要根据实际的业务场景设置不同的配比。例如对于问答类的模型,可以安排 25% 的推理,75% 的对话等等。
配套工具
unsloth:适合单机单卡;
vLLM 或 Ollama:用来部署微调后的模型;其他选择有 TensorRT
EvalScope:用来评估微调效果;
wandb:用来实时收集训练数据,观测微调过程中的各效指标变化;
1 2 3
1 2 3 4 5 6 7 8 'max_tokens' : 30000 , 'temperature' : 0.6 , 'top_p' : 0.95 , 'top_k' : 20 , 'n' : 1 ,
模型评估
使用 evalscope 及数据集进行评测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from evalscope import TaskConfig, run_task"./Qwen3-8B-unsloth-bnb-4bit" ,"http://127.0.0.1:8000/v1/chat/completions" ,"openai_api" ,"data_collection" ,"data_collection" : {"dataset_id" : "evalscope/Qwen3-Test-Collection" ,"filters" : {"remove_until" : "</think>" }, 8 ,"max_tokens" : 2048 , "temperature" : 0.6 , "top_p" : 0.95 , "top_k" : 20 , "n" : 1 , 60000 , True , 200 ,
MCP 微调
问:调用 MCP 的多轮对话场景如何进行微调训练?
答:直接将工具调用和回复做为数据的一部分,转换成标志符号,模型可以识别。此时数据中会出现多个 assistant 标记;
串联调用示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 {"messages" : ["role" : "user" ,"content" : "北京明天适合出门吗?" "role" : "assistant" ,"content" : null,"tool_calls" : ["id" : "call_1" ,"type" : "function" ,"function" : {"name" : "get_weather" ,"arguments" : "{\"location\": \"北京\", \"date\": \"明天\"}" "role" : "tool" ,"tool_call_id" : "call_1" ,"name" : "get_weather" ,"content" : "{\"temperature\": 5, \"condition\": \"晴\", \"precipitation\": 0}" "role" : "assistant" ,"content" : null,"tool_calls" : ["id" : "call_2" ,"type" : "function" ,"function" : {"name" : "assess_outdoor_suitability" ,"arguments" : "{\"temperature\": 5, \"condition\": \"晴\", \"precipitation\": 0}" "role" : "tool" ,"tool_call_id" : "call_2" ,"name" : "assess_outdoor_suitability" ,"content" : "{\"suitable\": true, \"reason\": \"天气晴朗,无降水,适合户外活动\"}" "role" : "assistant" ,"content" : "北京明天天气晴朗,气温5°C,无降水,非常适合出门!"
并联调用示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 {"messages" : ["role" : "user" ,"content" : "查一下北京明天的天气和空气质量。" "role" : "assistant" ,"content" : null,"tool_calls" : ["id" : "call_1" ,"type" : "function" ,"function" : {"name" : "get_weather" ,"arguments" : "{\"location\": \"北京\", \"date\": \"明天\"}" "id" : "call_2" ,"type" : "function" ,"function" : {"name" : "get_air_quality" ,"arguments" : "{\"city\": \"北京\"}" "role" : "tool" ,"tool_call_id" : "call_1" ,"name" : "get_weather" ,"content" : "{\"temperature\": 5, \"condition\": \"晴\"}" "role" : "tool" ,"tool_call_id" : "call_2" ,"name" : "get_air_quality" ,"content" : "{\"aqi\": 75, \"level\": \"良\"}" "role" : "assistant" ,"content" : "北京明天天气晴朗,气温5°C;空气质量良好(AQI 75),适合外出。"
能力遗忘
模型在出厂的时候,一般已经针对通用任务调整到了最佳状态。考虑到模型参数的限制,一般很难再让模型在记住旧知识的前提,学习新的知识,相当于模型参数的表达能力已经处于一个饱和的状态了。此时再使用垂直领域的数据进行微调,通常多多少少会造成原有能力的遗忘。微调训练所使用的垂直领域数据集越大,遗忘发生的可能性越高。总的来说,需要进行权衡和取舍。
提示工程
提示一般由以下三部分组成:
描述:详细描述任务目标、任务要求、输入格式、输出格式,用于向大模型解释清楚任务;
示例:为模型提供示范,进一步对齐上一步的描述;
输入:待解决的问题;
一些提示词技术:
少样本提示
思维链提示
自洽性提示:要求模型生成多个答案,然后再从中选择最佳答案;
思维树提示:要求模型生成多个解决问题的步骤或方法,然后再对这些方法进行评估;
CoT 思维链
Chain of Thought,思维链;它其实是一种提示词技巧,引导模型将一个复杂的大任务,拆分成多个小任务进行处理。它有几种实现方式:
零样本:在提出问题后,仅在最后附加一句咒语:Let’s think step by step。这句咒语会激发模型调用过往训练过程中见到过的推理样本(例如解数学题等),模型会按照习得的推理模式进行思考;
小样本:在提出问题前,附加 1-2 个示例,引导模型参照示例进行处理;每个示例包括:问题、推理过程、最终答案等内容;
自洽性:对小样本的进一步改进。相当于在示例中,罗列出多种解题方法,让模型参考该方法,从多个角度寻找答案,最终综合不同结果,选择最可能正确的那个答案;
复杂思维树:ToT,Tree of Thought,对自洽性的进一步改进。拆分多个步骤,每个步骤罗列多种可能方案,评估各方案,选择最可能正确的那个,一步一步的深入;相当于模拟人类的思考过程;
ReAct 推理&行动
Reasoning & Action,推理+行动,它也是一种提示词工程(技巧)。相比 CoT,它引入了动作,并且更加系统化或者说结构化,是一种更加高级的提示词策略。它遵循一个固定的范式,即采取动作前,先基于信息进行思考,判断自己下一步应该采取哪个动作。执行动作后,根据得到的信息,再次进行这个“思考->行动"的循环,直至思考结果为采取给出最终答案的动作,循环结束。
给出最终答案也可以视为一个特定类型的动作。其他动作则由预先定义好的各种函数组成,封装成工具 tool,以便供框架进行调用。
示例如下:
问题:爱因斯坦获得诺贝尔奖的年份比他发表狭义相对论晚多少年?
Thought: 我需要先找出爱因斯坦发表狭义相对论的年份,然后再找出他获得诺贝尔奖的年份,最后计算两者之差。Action: SearchEngine(query=“爱因斯坦 狭义相对论 发表年份”)Observation: 爱因斯坦于1905年发表狭义相对论。Thought: 现在我知道了发表狭义相对论的年份是1905年。接下来,我需要查找他获得诺贝尔奖的年份。Action: SearchEngine(query=“爱因斯坦 获得诺贝尔奖 年份”)Observation: 爱因斯坦于1921年获得诺贝尔物理学奖。Thought: 现在我有了两个年份:1905年和1921年。我可以计算它们之间的差值了。Action: PythonInterpreter(code=“1921 - 1905”)Observation: 16Final Answer: 爱因斯坦获得诺贝尔奖的年份比他发表狭义相对论晚了16年。
多模态 RAG
常见步骤:
PDF 解析
提取多模态信息
转 Markdown:能够保留语义结构,也方便后续提取;
文档切分
混合检索
RAG 的几种类型:
GraphRAG:会生成知识图谱,适合复杂领域的知识;
AgenticRAG:Agent 和 RAG 的结合;
多模态RAG:能够同时处理文本、图像、视频、音频、表格、公式等不同格式的输入和输出;
文档解析
涉及的工作
分析版面:使用专门的 OCR 或版面分析模型
提取层次结构;
提取图表;
融合多模态信息进行建模;
关于图片的处理,不仅仅是提取图片,还需要分析图片中的内容,这个比较有挑战;主要有两种处理方案:
OCR:擅长识别光学字符,能够很好的提取文字(手写或打印都可以),但无法实现图片的语义理解;
VLM 模型:能够很好的实现图片内容的理解,但是需要调用大模型,成本比较高;
几种 PDF 解析方法:
方法一:基于结构的完整重建
分析版面
分离元素;
内容识别和筛选;
格式转换:转成 Markdown,以便保留结构;
优点:结构完整,适合学术论文、报告、书籍等结构化程度高的文档;
方法二:图文切分+并行存储
PDF 按页面、段落、图片、表格进行切分;
文本直接转向量;
图片转存为图片向量(使用专用模型,如 CLIP、BLIP2等)
检索时也分开并行检索;
最终融合输出;
方法三:提取知识形成图谱
解析 PDF 后,使用单独的模型抽取知识单元,以便识别关键的实体、关系和事件;
将知识单元和上下文存入向量库,方便后续的语义化和结构化检索;
相关模型
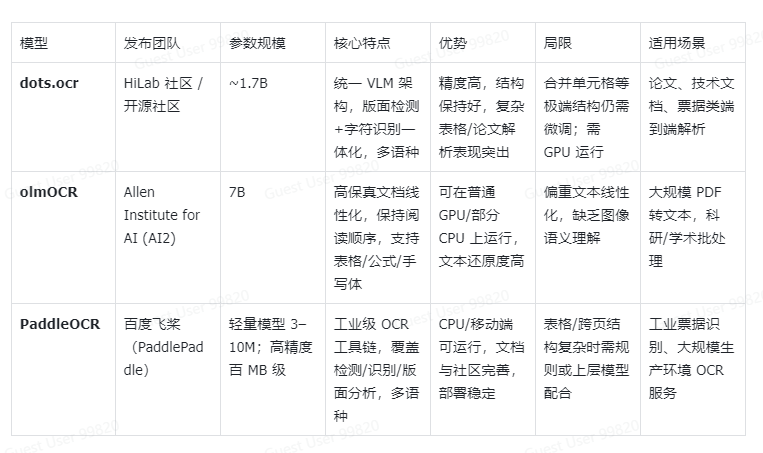
一些热门的 OCR 模型
dots.orc:小红书出品,端到端的模型,使用 VLT 架构(Vision Language Transformer),将检测、识别、建模等工作合并在一个模型中,减少了不同模块之间的对齐误差。模型只有 1.7B 的参数规模,非常轻量。
olmOCR:最大限度保留原文档内容的顺序性,但无法提取图片的语义,需要额外的 VLM 模型协助。
PaddleOCR:模型生态丰富,广泛使用。模型非常轻量,可在 CPU 上面运行。识别文本能力很强,但复杂图表、跨页关系需要额外处理;
一些热门的 VLM 模型
多模态 PDF 转 Markdown 模型
AgenticRAG
传统 RAG 的响应逻辑比较单一,检索 + 生成;但如果是一个复杂的问题,则可能涉及多步推理,例如:“xxx 名星的母校的建校年份是什么时候”。AgenticRAG 是一种新的 RAG 范式,它支持多步推理,能够先问问题拆分成多个小任务,再逐个寻找信息,最终再拼接成完整的答案。
上下文工程:
检索;
内容护栏:判断相关性
重写:若相关性不高,或者没有检索到内容,则可能需要重写问题。
生成答案;
以上工作可以编写多个函数完成,然后注册为 LangGraph 的节点,组装成 Agent 及工作流。
LangGraph
对于复杂的任务, 可能需要迭代多次才能完成任务. 每一轮迭代后, 需要进行判断, 看是否已经达到预期目标, 如果没有, 则需再次迭代;如果有, 则进入下一个环节. 对于这种情况, LangGraph 可以很好的对其进行管理(类似状态机)。
简单示例
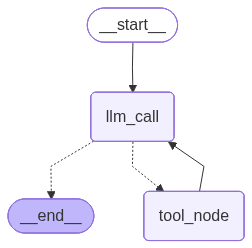
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 from dotenv import load_dotenvfrom langchain.tools import toolfrom langchain.chat_models import init_chat_modelfrom langchain.messages import AnyMessage, SystemMessage, ToolMessage, HumanMessagefrom typing_extensions import TypedDict, Annotatedimport operatorfrom typing import Literal from langgraph.graph import StateGraph, START, END"deepseek-chat" , model_provider="deepseek" , temperature=0 )@tool def multiply (a: int , b: int ) -> int :"""Multiply `a` and `b`. Args: a: First int b: Second int """ return a * b@tool def add (a: int , b: int ) -> int :"""Add `a` and `b`. Args: a: First int b: Second int """ return a + b@tool def divide (a: int , b: int ) -> int :"""Divide `a` and `b`. Args: a: First int b: Second int """ return a / bfor tool in tools}class MessageState (TypedDict ):list [AnyMessage], operator.add]int def llm_call (state: dict ):"""由模型自行决定是否调用工具""" return {"messages" : ["You are a helpful assistant tasked with performing arithmetic on a set of inputs." "messages" ]"llm_calls" : state.get("llm_calls" , 0 ) + 1 ,def tool_node (state: dict ):"""调用工具""" for tool_call in state["messages" ][-1 ].tool_calls:"name" ]]"args" ])"id" ]))return {"messages" : result}def should_continue (state: MessageState ) -> Literal ["tool_node" , "end" ]:"""判断是否应该继续循环, 还是结束""" "messages" ]1 ]if last_message.tool_calls:return "tool_node" return END"llm_call" )"tool_node" )"llm_call" )"llm_call" , should_continue, ["tool_node" , END])"tool_node" , "llm_call" )compile ()"Add 3 and 4." )]"messages" : messages})for m in messages["messages" ]:
1 2 3 4 5 6 7 from PIL import Imageimport ioTrue ).draw_mermaid_png()open (io.BytesIO(png_bytes))
基本流程
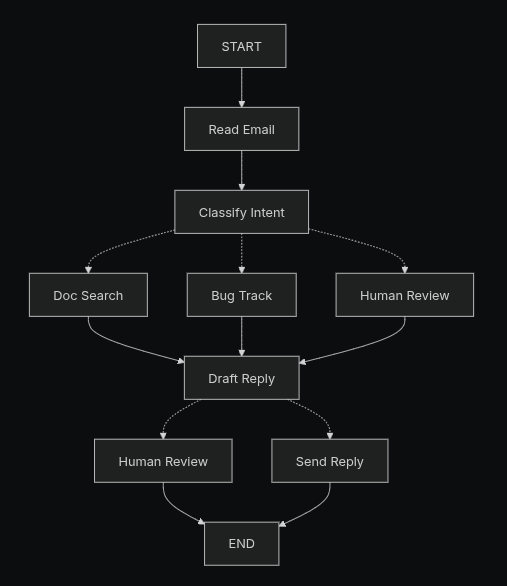
假设构建一个自动回复邮件的智能体
设计工作流
设计节点
对于工作流中的每个节点, 确定其操作类型和需要哪些上下文, 操作类型包括:
LLM: 负责语义分析, 内容生成, 或者推理;
数据检索: 从外部数据源中检索数据, 例如从数据库中查询信息;
动作: 执行外部动作, 例如发送邮件, 创建工单等;
用户输入: 获取用户的输入, 例如人工确认后, 再进入下一步;或者给出多个选项, 由用户选择下一步要执行的动作;
设计状态
状态: 用于在各个节点之间共享数据;节点可基于状态中的信息, 知道过去发生了什么, 以及判断下一步需要做什么;
状态中应保持原始数据, 而不是节点需要的格式化数据. 因为每个节点需要的格式可能不同, 因此二者最好解耦
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from typing import TypedDict, Literal class EmailClassification (TypedDict ):Literal ["question" , "bug" , "billing" , "feature" , "complex" ]Literal ["low" , "medium" , "high" , "critical" ]str str class EmailAgentState (TypedDict ):str str str None list [str ] | None dict | None str | None list [str ] | None
创建节点
所谓的节点, 其实是一个 Python 函数, 它以 State 作为输入, 执行相关的动作, 之后更新 State
处理异常
不同类型的异常, 需要不同的处理策略
异常类型
由谁处理
策略
何时使用
瞬时错误, 如网络中断, 限流等
系统
重试
重试后通常可自动恢复
LLM 可恢复错误, 如工具调用失败, 输出解析问题
LLM
将错误存储到状态中, 重新进入循环
LLM 从状态中看到错误后自行处理
用户可修复错误, 例如输入不完整, 信息缺失, 指令有歧义等
人工
使用 interrupt() 暂停
待用户纠正后再继续,, 因为系统无法自动纠正
预期外的错误
开发者
冒泡
Debug
1 2 3 4 5 6 7 8 from langgraph.types import RetryPolicy"search_documentation" ,3 , initial_interval=1.0 )
1 2 3 4 5 6 7 8 9 10 11 12 13 from langgraph.types import Commanddef execute_tool (state: State ) -> Command[Literal ["agent" , "execute_tool" ]]:try :"tool_call" ])return Command(update={"tool_result" : result}, goto="agent" )except :return Command("tool_result" : f"Tool error: {str (e)} " },"agent"
1 2 3 4 5 6 7 8 9 10 11 12 13 def lookup_customer_history (state: State ) -> Command[Literal ["draft_response" ]]:if not state.get("customer_id" ):"message" : "需要提供客户ID" ,"request" : "请提供客户ID, 以便查询订阅记录" return Command("customer_id" : user_input["customer_id" ]},"lookup_customer_history" "customer_id" ])return Command(update={"customer_history" : customer_data}, goto="draft_response" )
1 2 3 4 5 6 def send_reply (state: EmailAgentState ):try :"draft_response" ])except Exception:raise
编写节点
节点即函数, 接受 state 参数, 执行相关的动作, 返回更新
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 from typing import Literal from langgraph.graph import StateGraph, START, ENDfrom langgraph.types import interrupt, Command, RetryPolicyfrom langchain_openai import ChatOpenAIfrom langchain.messages import HumanMessage"gpt-5-nano" )def read_email (state: EmailAgentState ) -> dict :"""提取并解析邮件中的内容""" return {"messages" : [f"Processing email: {state['email_content' ]} " )def classify_intent (state: EmailAgentState ) -> Command[Literal ["search_documentation" , "human_review" , "draft_response" , "bug_tracking" ]]:"""使用 LLM 解析邮件的意图, 并对紧急程度进行分类""" f""" 分析该客户的邮件并进行紧急程度的分类: Email: {state['email_content' ]} From: {state['email_sender' ]} 提供分类信息, 包括邮件目的, 紧急程度, 主题和摘要. """ "intent" ]"urgency" ]if intent = "billing" or urgentcy == "critical" :"human_interview" elif intent in ["question" , "feature" ]:"search_documentation" elif intent = "bug" :"bug_tracking" else :"draft_response" return Command(update={"classification" : classification}, goto=goto)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def search_documentation (state: EmailAgentState ) -> Command[Literal ["draft_response" ]]:"""从知识库中检索相关信息""" "classification" , {})f"{classification.get('intent' , '' )} {classification.get('topic' , '' )} " try :"Reset password via Settings > Security > Change Password" ,"Password must be at least 12 characters" ,"Include uppercase, lowercase, numbers, and symbols" ,except SearchAPIError as e:f"Search temporarily unavailable: {str (e)} " ]return Command("search_results" : search_results}, "draft_response" ,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def bug_tracking (state: EmailAgentState ) -> Command[Literal ["draft_response" ]]:"""创建异常处理的工单""" "BUG-12345" return Command("search_results" : [f"Bug ticket {ticket_id} created" ],"current_step" : "bug_tracked" ,"draft_response" ,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 def draft_response ( state: EmailAgentState, Literal ["human_review" , "send_reply" ]]:"""根据收集到的信息, 撰写回复邮件""" "classification" , {})if state.get("search_results" ):"\n" .join([f"- {doc} " for doc in state["search_results" ]])f"相关文档:\n{formatted_docs} " )if state.get("customer_history" ):f"顾客等级: {state['customer_history' ].get('tier' , 'standard' )} " f""" Draft a response to this customer email: {state['email_content' ]} 邮件目的: {classification.get('intent' , 'unknown' )} 紧急程度: {classification.get('urgency' , 'medium' )} {chr (10 ).join(context_sections)} 指南: - 保持专业, 为顾客提供帮助; - 解决顾客的具体问题 - 适时参考文档 """ "urgency" ) in ["high" , "critical" ]or classification.get("intent" ) == "complex" "human_review" if needs_review else "send_reply" return Command("draft_response" : response.content},
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 def human_review (state: EmailAgentState ) -> Command[Literal ["send_reply" , END]]:"""暂停流程以进行人工审核,并基于审核结果进行路由""" "classification" , {})"email_id" : state.get("email_id" , "" ),"original_email" : state.get("email_content" , "" ),"draft_response" : state.get("draft_response" , "" ),"urgency" : classification.get("urgency" ),"intent" : classification.get("intent" ),"action" : "请审核通过或改写邮件内容" ,if human_decision.get("approved" ):return Command("draft_response" : human_decision.get("edited_response" , state.get("draft_response" , "" )"send_reply" ,else :return Command(update={}, goto=END)
1 2 3 4 5 6 def send_reply (state: EmailAgentState ) -> dict :"""发送邮件内容""" print (f"Sending reply: {state['draft_response' ][:100 ]} ..." )return {}
整合节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from langgraph.checkpoint.memory import MemorySaverfrom langgraph.types import RetryPolicy"read_email" , read_email)"classify_intent" , classify_intent)"search_documentation" ,3 )"bug_tracking" , bug_tracking)"draft_response" , draft_response)"human_review" , human_review)"send_reply" , send_reply)"read_email" )"read_email" , "classify_intent" )"send_reply" , END)compile (checkpointer=memory)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 "email_content" : "重复扣款了!急急急!" ,"sender_email" : "customer@example.com" ,"email_id" : "email_123" ,"messages" : []"configurable" : {"thread_id" : "customer_123" }}print (f"human review interrupt:{result['__interrupt__' ]} " )from langgraph.types import Command"approved" : True ,"edited_response" : "实在非常抱歉重复扣款了, 我们将马上给您安排退款, 感谢您的耐心等待!" print (f"Email sent successfully!" )